[번역] Sequence Assembly - 염기서열 조립, 유전체 조립
이 글은 위키피디아의 Sequence Assembly 항목을 번역한 것입니다. 영어 원문은 여기서 찾으실 수 있습니다.
주의) 생명정보학은 빠르게 발전하는 학문이며, 본 위키피디아 글은 예전에 작성되었기 때문에 현재 발전된 기술 및 소프트웨어들은 생략이 많이 되어있습니다.
생명정보학에서, 염기서열 조립 (sequence assembly)는 본래의 염기서열을 알아내기 위해 조각들을 정렬하고 합쳐서 더 기다란 DNA 서열로 만드는 것을 의미한다. 이것은 DNA 시퀀싱 기술이 한 번에 유전체 전체를 읽을 수가 없고, 사용하는 기술에 따라, 20에서 30,000 베이스 사이의 작은 조각들로만 읽을 수가 있기 때문이다. Reads라고 불리는 이 작은 조각들은 주로 유전체나 EST나 샷건 시퀀싱 (shotgun sequencing) 하는 것으로부터 생긴다.
유전체 조립 문제를 비유하자면, 같은 책 여러 권을 각각 다른 분쇄기에 파쇄한 다음, 그 조각들만 가지고 책의 내용을 파악하는 것과 같다. 이 작업의 당연한 어려움에 더불어서, 실제적으로도 몇 가지 추가적인 문제가 있다: 1) 원본은 내용이 똑같은 문단이 몇 번씩 반복된다. 2) 조각들 중에 조각내는 과정에서 생긴 오탈자가 있다. 3) 다른 책에서 생긴 조각이 들어갈 가능성도 있다. 그리고 4) 몇몇 조각들은 아예 알아볼 수가 없다.
목차 - Contents
1 유전체 조립 도구 (어셈블러) Genome assemblers
2 EST 조립 도구 EST assemblers
3 데노보와 맵핑 조립 De-novo vs. mapping assembly
4 기술 발전의 영향 Influence of technological changes
5 탐욕적 알고리즘 Greedy algorithm
6 유전체 조립 도구의 예 Notable assemblers
7 외부 링크 See also
8 참조 문헌 References
1. 유전체 조립 도구 (어셈블러) - Genome assemblers
최초의 시퀀스 어셈블러는 1980년대 후반과 1990년대 초반에 programs to piece together vast quantities of fragments generated by automated sequencing instruments called DNA 시퀀서 (DNA sequencers)로 불리는 자동 시퀀싱 기계가 출력해 낸 방대한 양의 조각들을 짜집기 위해 간단한 시퀀스 정렬 프로그램의 변형된 버전으로나오기 시작했다. 시퀀싱 하는 대상 생물이 크기와 복잡성에서 점차 증대 함에 따라, 이 유전체 프로젝트 (genome projects)에 필요한 어셈블러는 더욱 복잡한 방법이 필요하게 되었다. 컴퓨터 클러스터에서 수행할 테라바이트 급의 시퀀싱 데이터, 동일하거나 아주 비슷한 (반복 구간으로 불리는) 시퀀스들은, 최악의 경우에, 알고리즘의 시간과 리소스를 기하급수적으로 늘릴 수 있었고, 조각에 존재하는 시퀀싱 기계로 인한 에러들은, 어셈블리 자체를 혼란에 빠뜨릴 수 있었기 때문이다.
최초의 대형 진핵생물 유전체인 초파리 Drosophila melanogaster를 조립하는 데에 어려움을 맞이한 과학자들은 (2000년, 인간 유전체는 그 1년 후에 이뤄졌다) Celera Assembler[1] 와 Arachne[2] 같은 어셈블러를 개발하여서 1억에서 3억 베이스의 유전체를 다룰 수 있도록 하였다. 이 시도를 따라서, 몇몇의 다른 주요 유전체 시퀀싱 그룹들이 대규모의 어셈블러를 만들었고, AMOS[3] 와 같은 오픈소스 프로젝트도 시작되어서 오픈소스 체제에서 유전체 조립 기술의 최신 방법들을 도입하는 시도도 있었다.

염기서열 어셈블러가 어떻게 겹치는 부분으로 조각들을 갖다 맞추는지 보여주는 예제. 그림은 염기서열에 반복되는 부분이 있어서 생기는 문제도 보여준다.
2. EST 조립도구 - EST assemblers
Expressed Sequence Tag 혹은 EST 어셈블리는 유전체 어셈블리와는 여러가지 면에서 다르다. EST 시퀀스들은 세포의 전사된 mRNA이며 전체 유전체의 오직 일부분 만을 나타낸다. 유전체와EST의 어셈블리는 그 알고리즘 자체에서 달라보인다. 예를 들어, 유전체는 종종 반복되는 시퀀스들이 특히 유전자와 유전자 사이 부분에 대량으로 있다. EST가 유전자의 전사체를 나타내기 때문에, EST는 그러한 부분이 없다. 반면에, 세포는 일정한 수의 유전자들을 아주 대량으로 전사하는 경향이 있다 (housekeeping genes). 그리고 이것은 어셈블 해야할 데이터에 비슷한 시퀀스들이 다수가 존재한 다는 것을 의미한다.
더군다나, 유전자는 때때로 유전체에서 겹치는 부분이 존재하기도 하지만 (sense-antisense transcription), 이상적으로는 이 부분들을 유전자 별로 따로 조립해야 한다. EST 어셈블리는 또한 alternative splicing, trans-splicing, single-nucleotide polymorphism, post-transcriptional modification와 같은 문제들 때문에 더 복잡해 지기도 한다.
3. 데노보와 맵핑 조립 - De-novo vs. mapping assembly
시퀀스 어셈블리는 두가지의 종류로 나눌 수 있다:
데노보 (de-novo): 짧은 조각들을 맞춰서 완전한 길이의 (때때로는 새로운) 시퀀스들을 만드는 것 (De novo sequence assemblers, de novo transcriptome assembly 참조)
맵핑 (mapping): 조각들을 이미 존재하는 뼈대 시퀀스에 맞춰서 그 뼈대 시퀀스와 동일하지는 않지만 비슷한 전체 시퀀스를 만드는 것.
복잡성과 시간으로 봤을 때, 데노보 어셈블리는 맵핑 어셈블리보다 몇배나 느리고 메모리도 더 요구한다. 이것은 대부분 어셈블리 알고리즘이 모든 조각들을 모든 다른 조각들에 비교한다는 사실때문이다 ( O(n2)의 시간이 걸리지만, 해쉬를 이용하면 시간을 많이 단축할 수 있다). 앞서 나온 파쇄된 책과 비교한다면, 맵핑 어셈블리는 아주 비슷한 책이 견본으로 있는 것과 다름없다 (아마 주인공 이름과 지역 이름 정도는 바꼈을테지만). 데노보 어셈블리는 이 책이 과학 교과서인지, 소설인지, 카탈로그인지, 아니면 심지어 몇권이 섞여있는 지도 모르는 상태이므로 더 본격적으로 어렵다. 또한, 모든 파쇄조각들을 다른 파쇄조각들에 일일이 비교해야 하기도 한다.
4. 기술발전의 영향 - Influence of technological changes
시퀀스 어셈블리의 복잡함은 두가지 요인으로부터 결정된다: 조각의 갯수와 그 길이이다. 더 많고 더 긴 조각들은 더 많은 부분이 겹쳐서 더 나은 조립을 할 수 있게 되지만, 그것은 동시에 계산 알고리즘이 조각의 길이와 수에 따라 제곱 혹은 지수승으로 복잡해질 수 있기 때문에 문제를 일으킨다. 그리고 짧은 시퀀스들은 정렬하기에 빠르지만, 짧으면 짧을 수록 반복된 구간이나 비슷한 구간이 반복될 경우에 어셈블리를 더 복잡하게 만들기도 한다.
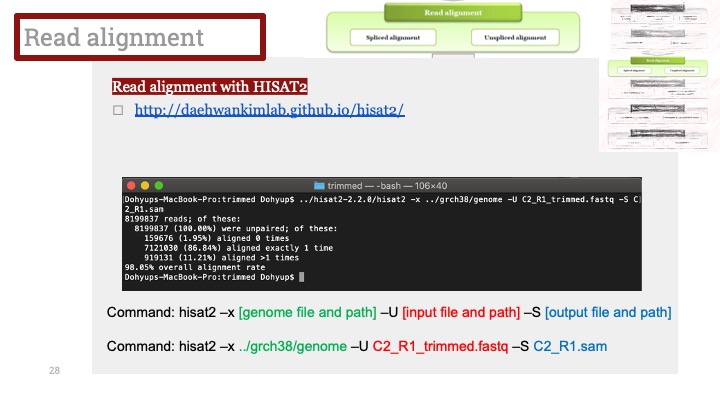
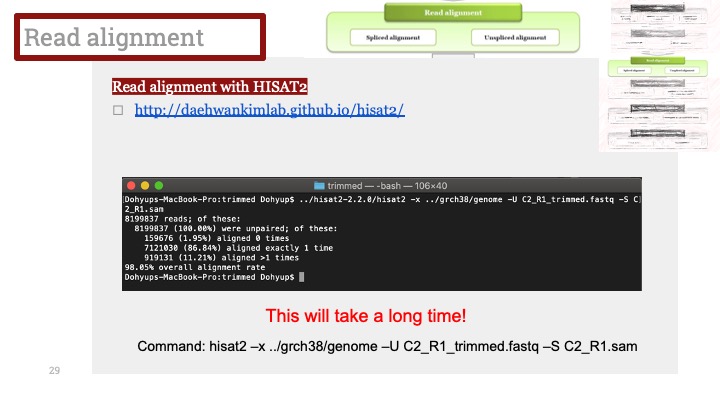
DNA 시퀀싱의 아주 초반에는, 과학자들이 실험실에서 몇주간 일한다음에야 짧은 길이의 (주로 수십 베이스의) 시퀀스들을 단지 몇개만 얻을 수 있었다. 그러므로, 그 시퀀스들을 정렬하는 데에는 수작업으로 몇 분밖에 걸리지 않았었던 것이다.
1975년에, Sanger sequencing으로 불리는 Dideoxy termination 방법이 개발 되었고, 2000년 쯤 까지 이 기술은 발전하여 완전히 자동으로 동작하는 기계들이 하루 24시간 내내 병렬적으로 시퀀싱을 가동할 수 있게 되었다. 전세계의 대형 유전체 센터들은 이 시퀀싱 기계들을 수백 수천대 가동하고 있었다. 그리고 그것은 조각의 길이가 800에서 900 베이스 정도 되고 시퀀싱 기계와 클로닝 벡터 (cloning vectors)에서 비롯한 에러율이 0.5에서 10퍼센트 정도 되는 유전체 전체 샷건 시퀀싱 프로젝트 (shotgun sequencing projects)에 최적화된 어셈블러를 개발하도록 만들었다.
Sanger sequencing 기술로 인해, 2만개에서 20만개의 조각을 가진 박테리아 유전체는 컴퓨터 한대에서 쉽게 어셈블리 할 수 있었다. 3천5백만개의 조각이 있는 인간 유전체같은 좀 더 큰 프로젝트들은 분산 컴퓨팅을 이용하여 대형 컴퓨터 센터가 필요했다.
2004, 2005년에, 454 Life Sciences의 파이로시퀀싱(pyrosequencing)이 상업적으로 이용가능하게되었다. 이 새로운 시퀀싱 기술은 Sanger 시퀀싱보다는 훨씬 더 짧은 조각들을 만들었지만 (그당시에는 약 100 베이스, 지금은 400-500베이스) 고속대용량에 가격도 저렴했기 때문에 (Sanger에 비해) 유전체 센터들은 이 기술을 많이 차용했다. 그리고 그것은 이러한 대량의 시퀀스 조각들을 효율적으로 처리할 수 있는 시퀀서의 개발을 이끌었다. 대용량의 데이터는, 그 기술에 특화한 에러 패턴과 더불어 어셈블러의 발전을 늦추게 하는 요소였다. 2004년 초반에는 454가 개발한 Newbler 어셈블러만이 사용가능 했다. 2007년 중반에 Chevreux et al.이 개발한 MIRA 어셈블러의 혼합버전이 454 시퀀스 어셈블리와 454 시퀀스와 Sanger가 혼합된 시퀀스 어셈블리가 가능한 최초의 무료 소프트웨어였다. 서로 다른 기술로 나온 시퀀스들을 어셈블리 하기 위해 하이브리드 어셈블리 hybrid assembly의 개념도 탄생하게 되었다.
2006년 부터, 일루미나 Illumina (전 Solexa) 기술이 가능하여져서 하나의 시퀀싱 기계에서 한번 돌릴때마다 1억개의 조각이 나오게 되었다. 인간 유전체 프로젝트의 3천5백만 조각이 이전에는 수백대의 기계로 몇년이 걸렸다는 것과 비교해보라. 일루미나 시퀀싱은 처음에는 36베이스로 조각길이가 제한되어 있었다. 이것은 데노보 어셈블리는 (de novo transcriptome assembly와 같은) 거의 불가능한 길이엇다. 하지만 새로운 기술은 이 조각 길이를 100베이스 이상으로 끌어올렸고, 2007년 말에는 Dohm et al.이 개발한 the SHARCGS assembler 가 Solexa read를 사용한 어셈블리를 하는 어셈블러로 최초로 발표되었다.
후에, SOLiD, Ion Torrent and SMRT와 같은 새로운 기술이 발표되었고, Nanopore sequencing과 같은 기술도 부상하고 있다.
5. 탐욕적 알고리즘 - Greedy algorithm
염기 서열 조각이 여러개 주어졌을 때에, 알고리즘의 목적은 가장 짧은 supersequence를 찾는 것이다.
1. 모든 조각을 1:1로 정렬해서 계산한다.
2. 가장 많이 겹치는 두 개의 조각을 고른다.
3. 선택한 조각을 겹쳐서 합친다.
4. 2와 3을 조각이 단 하나 남을 때까지 반복한다.
결과는 문제에 궁극적인 정답이 항상 되지는 않는다.
6. 유전체 어셈블러의 예 - Notable assemblers
아래의 표는 데노보 어셈블리가 가능한 유전체 어셈블러 몇몇의 예이다.
Name | Type | Technologies | Author | Presented /Last updated | Licence* |
DNASTAR Lasergene Genomics Suite | (large) genomes, exomes, transcriptomes, metagenomes, ESTs | Illumina, ABI SOLiD, Roche 454, Ion Torrent, Solexa, Sanger | DNASTAR | 2007 / 2016 | C |
Newbler | genomes, ESTs | 454, Sanger | 454/Roche | 2004/2012 | C |
Phrap | genomes | Sanger, 454, Solexa | Green, P. | 1994 / 2008 | C / NC-A |
SPAdes | (small) genomes, single-cell | Illumina, Solexa, Sanger, 454, Ion Torrent, PacBio, Oxford Nanopore | Bankevich, A et al. | 2012 / 2017 | OS |
Velvet | (small) genomes | Sanger, 454, Solexa, SOLiD | Zerbino, D. et al. | 2007 / 2011 | OS |
*Licences: OS = Open Source; C = Commercial; C / NC-A = Commercial but free for non-commercial and academics |
7. 외부 링크 - See also
De novo sequence assemblers
Sequence alignment
De novo transcriptome assembly
Set cover problem
List of sequenced animal genomes
8. 참조 - References
Myers, E. W.; Sutton, GG; Delcher, AL; Dew, IM; Fasulo, DP; Flanigan, MJ; Kravitz, SA; Mobarry, CM; et al. (March 2000). "A whole-genome assembly of Drosophila". Science. 287 (5461): 2196–204. Bibcode:2000Sci...287.2196M. PMID 10731133. doi:10.1126/science.287.5461.2196.
Batzoglou, S.; Jaffe, DB; Stanley, K; Butler, J; Gnerre, S; Mauceli, E; Berger, B; Mesirov, JP; Lander, ES (January 2002). "ARACHNE: a whole-genome shotgun assembler". Genome Research. 12 (1): 177–89. PMC 155255 PMID 11779843. doi:10.1101/gr.208902.
AMOS page with links to various papers
Copy in Google groups of the post announcing MIRA 2.9.8 hybrid version in the bionet.software Usenet group
Dohm, J. C.; Lottaz, C.; Borodina, T.; Himmelbauer, H. (November 2007). "SHARCGS, a fast and highly accurate short-read assembly algorithm for de novo genomic sequencing". Genome Research. 17 (11): 1697–706. PMC 2045152 PMID 17908823. doi:10.1101/gr.6435207.
list of software including mapping assemblers in the SeqAnswers discussion forum.