
이 글은 Kaggle의 머신러닝 입문 (Intro to Machine Learning) 강의를 번역/정리한 글입니다. 원문은 여기서 찾아보실 수 있습니다.
이전 글은 아래에서 보실 수 있습니다.
파이썬 Pandas로 머신러닝 기초 배워보기 (1/5): https://ruins880.tistory.com/78
파이썬 Pandas로 머신러닝 기초 배워보기 (1/5)
이 글은 Kaggle의 머신러닝 입문 (Intro to Machine Learning) 강의를 번역/정리한 글입니다. 원문은 여기서 찾아보실 수 있습니다. Introduction 먼저, 머신러닝에서 모델이 어떻게 사용되는지 부터 시작하겠
ruins880.tistory.com
Selecting Data for Modeling
지금 우리가 가진 데이터는 너무 변수가 많습니다. 이렇게 많은 양의 데이터에서 이해가 가능한 정보를 빼내려면 어떻게 해야할까요? 일단, 느낌으로 변수를 몇 개 골라보겠습니다. 나중에는 통계적 방법으로 변수를 선택하는 것을 배우게 될 것입니다.
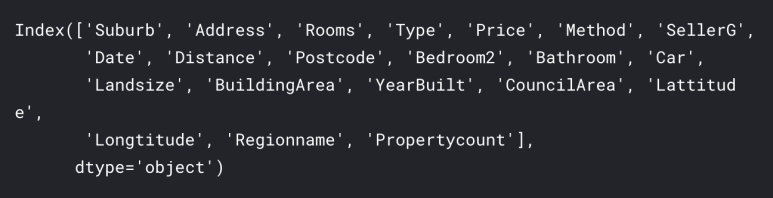
우리 데이터에서 변수를, 혹은 열을 고르려면 모든 열(column)들을 봐야겠죠. 다음의 코드로 DataFrame에서 모든 column을 볼 수 있습니다.
|
import pandas as pd
melbourne_file_path = '../input/melbourne-housing-snapshot/melb_data.csv'
melbourne_data = pd.read_csv(melbourne_file_path)
melbourne_data.columns
|
|
# 멜버른 데이터에는 비어있는 값들이 있습니다 (어떤 집들에는 몇몇 변수들이 기록이 되어있지 않죠).
# 나중에 이러한 빠진 값들을 다루는 방법을 배울 것입니다.
# 아이오와 데이터에서 우리가 사용하는 열에는 빠진 값들이 없습니다.
# 그러므로 지금은 가장 간단하게, 값이 없는 집들을 애초에 빼버리겠습니다.
# 지금은 너무 신경쓰지 않아도 되지만, 코드는 다음과 같습니다:
# dropna 명령어는 비어있는 줄을 빼버립니다 (na는 "not available"이라고 생각하세요)
melbourne_data = melbourne_data.dropna(axis=0)
|
데이터의 일부분을 선택하는 데에는 여러가지 방법이 있습니다. Pandas 강의에 더 자세히 나와있지만, 지금은 두가지 방법을 사용하겠습니다.
1. Dot notation: "Prediction target"을 선택하는 데에 이용
DataFrame에서는 dot-notation을 이용하여 변수를 선택할 수 있습니다. 선택된 하나의 열은 Series 형태로 저장됩니다. 우리가 예측하고 싶은 변수인 prediction target을 이 방법을 사용하여 선택하고 y 변수에 저장해보겠습니다. 집값을 저장하는 코드는 다음과 같습니다:
|
y = melbourne_data.Price
|
2. Selecting with a column list: "feature"를 선택하는 데에 이용
모델에 입력하여서 나중에 예측하는 데에 사용되는 변수열들은 "features"라고 부릅니다. 우리 예제의 경우에는 이러한 features를 사용하여 prediction target인 집값을 결정하는 데 쓸 것입니다. 종종 우리가 가진 모든 변수들을 예측모델에 쓰기도 하지만, 어떤 경우에는 몇몇의 변수들만 선택하는 것이 더 나을 때도 있습니다.
지금은 몇 개의 중요한 feature들만 선택해 보겠습니다. 여러개의 feature를 선택하는 방법은 대괄호를 쓰는 것입니다. 각각의 feature 이름은 아래의 예제처럼 큰따옴표를 이용하여야 합니다.
|
melbourne_features = ['Rooms', 'Bathroom', 'Landsize', 'Lattitude', 'Longtitude']
X = melbourne_data[melbourne_features]
|
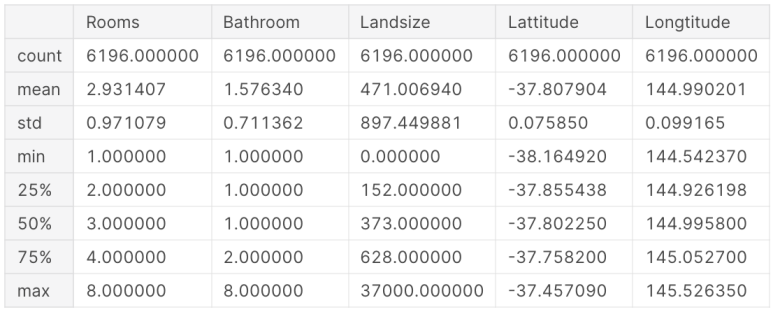
X에 저장된 데이터를 describe와 head 명령어로 살펴보겠습니다.
|
X.describe()
|
|
X.head()
|
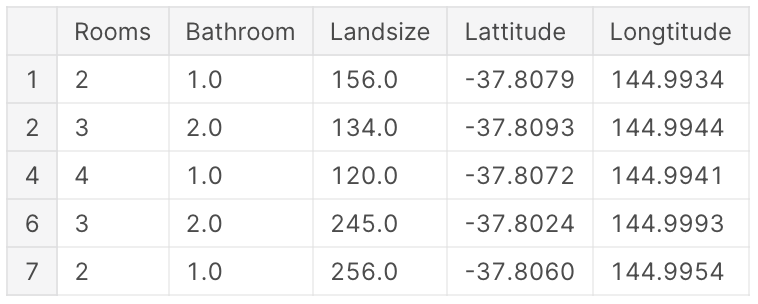
이렇게 시각적으로 데이터를 살펴보는 과정은 아주 중요합니다. 데이터에서 어떤 것을 발견할 지 모르거든요.
Building Your Model (모델 만들어 보기)
모델을 만들기 위해 scikit-learn 라이브러리를 사용하겠습니다. 예제 코드에 나와있듯이, 실제 코딩에서는 sklearn으로 씁니다. Scikit-learn 라이브러리는 DataFrame 유형의 자료를 가지고 모델을 만드는 데에 가장 널리 쓰이는 라이브러리 입니다. 모델을 만들고 이용하는 과정은 다음과 같습니다:
* Define (정의하기): 어떤 유형의 모델을 만들 것인가요? 처음에 배운 Decision Tree, 혹은 다른 새로운 모델?
* Fit (적합시키기): 제공된 데이터에서 패턴을 찾습니다. 가장 핵심인 단계입니다.
* Predict (예측하기): 말 그대롭니다.
* Evaluate (평가하기): 모델이 예측한 결과가 얼마나 정확한지 알아봅니다.
다음은 scikit-learn 라이브러리를 이용하여 모델을 정의하고 우리의 데이터에 적합시키는 예제 코드입니다.
|
from sklearn.tree import DecisionTreeRegressor
# 모델을 정의합니다. 매번 똑같은 결과를 얻기 위해 random_state에 숫자를 지정합니다.
melbourne_model = DecisionTreeRegressor(random_state=1)
# 모델을 데이터에 적합시킵니다.
melbourne_model.fit(X, y)
|
머신러닝에 쓰이는 많은 모델들은 그 적합과정에서 어느정도 무작위성(randomness)을 포함합니다. random_state로 숫자를 지정하면, 실행할 때마다 같은 결과를 가지도록 해줍니다. 이것은 좋은 습관이죠. 하지만 어떤 수를 지정하든 모델 자체에는 의미있는 변화를 주지는 않습니다.
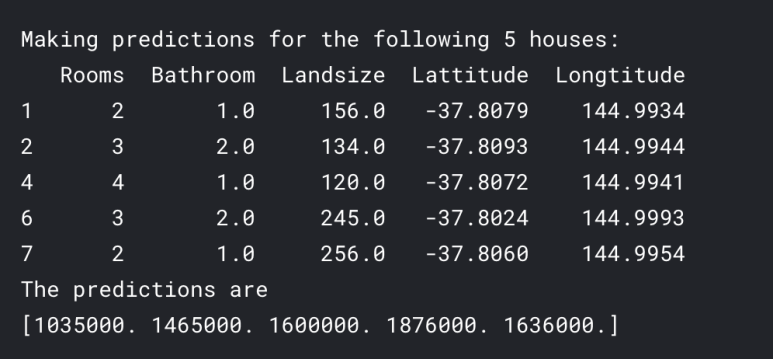
실제로는, 지금 이미 집값이 나와있는 집 말고, 앞으로 매물이 나오는 집의 집값을 예측하는 것이 우리의 목표입니다. 하지만 지금은, 우리가 가지고 있는 데이터에서 집값이 어떻게 계산되는지 처음 몇 줄의 결과를 보겠습니다.
|
print("Making predictions for the following 5 houses:")
print(X.head())
print("The predictions are")
print(melbourne_model.predict(X.head()))
|
다음은 직접 예제를 실행해 보겠습니다.
Kaggle은 따로 컴퓨터에 설치할 필요없이 웹상에서 파이썬 코드를 작성하고 실행시킬 수 있는 "notebook" 환경을 이용합니다. notebook 환경이 처음이신 분은 다음의 짧은 동영상을 보시면 됩니다: https://www.youtube.com/watch?v=4C2qMnaIKL4

지난 예제에서, 다음과 같이 데이터를 불러오고 확인하였습니다. 예제를 이어서 하기 위해 다음 코드를 실행시켜주세요.

Exercises
이번 예제는 직접 간단한 모델을 만들어 보겠습니다. 예제는 아래의 링크에서 직접해보실 수 있습니다. Kaggle 계정을 생성하시면 더 도움이 될 수 있습니다.
Step 1: Specify Prediction Target (예측할 타겟을 지정하기)

Step 2: Create X (X 변수 생성하기)
이제 이름이 X인 DataFrame을 생성하여 예측에 필요한 feature들을 저장할 것입니다.
원래의 데이터에서 일부분만 저장할 것이므로, 일단 X에 들어갈 열 이름들을 리스트로 만들어 보겠습니다. 다음의 변수 이름들을 사용해서 리스트를 만드세요.
* LotArea * YearBuilt * 1stFlrSF * 2ndFlrSF * FullBath * BedroomAbvGr * TotRmsAbvGrd
리스트를 만든 다음, 그것을 사용하여 DataFrame을 만들어 보세요.

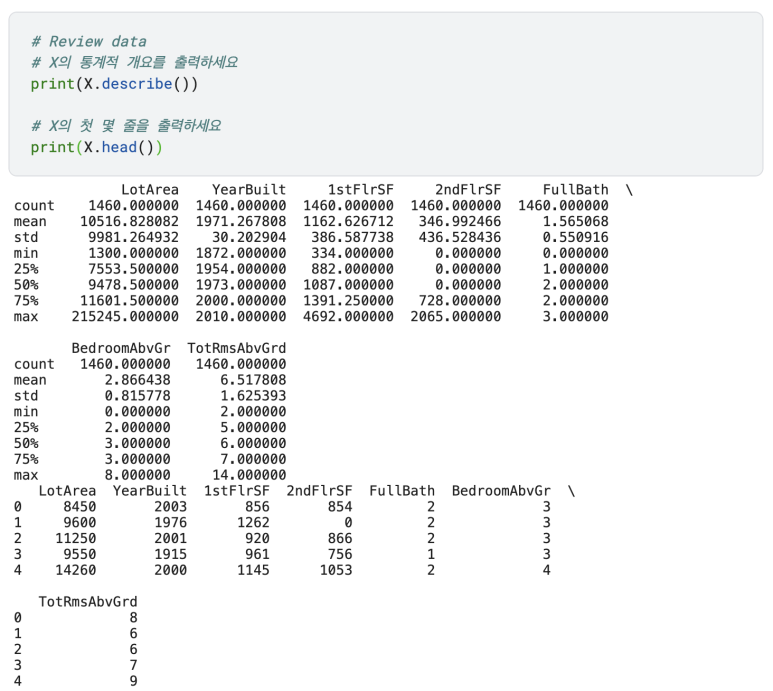
Review Data(데이터 확인하기)
모델을 만들기 전, X를 출력하여 괜찮아 보이는지 확인해 봅시다.
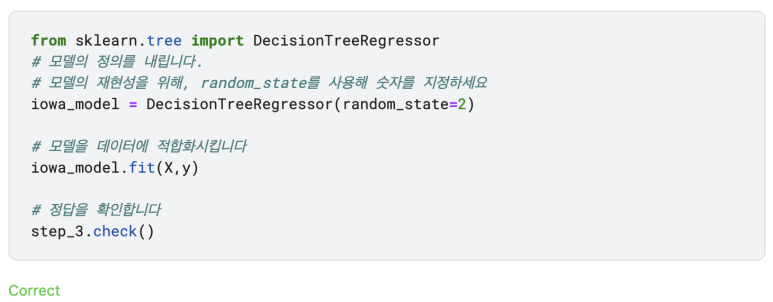
Step 3: Specify and Fit Model (모델을 지정하고 적합화 시키기)
DecisionTreeRegressor를 생성하여 iowa_model을 저장하세요. sklearn 라이브러리를 불러오는 것도 잊지마세요. 그런 다음, X에 있는 데이터를 가지고, y에 저장한 모델을 적합화시키세요.
Step 4: Make Predictions (예측하기)
predict 명령어로 X를 사용하여 예측을 해봅시다. 결과는 predictions 변수에 저장하세요.

Think About Your Results (결과에 대하여 생각해보기)
head 명령으를 사용해 예측한 결과와 실제 집값을 비교해봅시다.
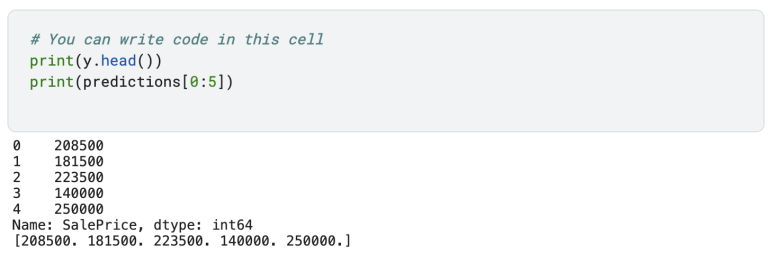
특별한 점이 있나요? 모델의 정확성을 따지고 어떻게 더 정확하게 만들지를 생각하게 됩니다. 그것이 다음 단계입니다.
파이썬 Pandas로 머신러닝 기초 배워보기 (3/5): https://ruins880.tistory.com/80
파이썬 Pandas로 머신러닝 기초 배워보기 (3/5)
이 글은 Kaggle의 머신러닝 입문 (Intro to Machine Learning) 강의를 번역/정리한 글입니다. 원문은 여기서 찾아보실 수 있습니다. 이전 글은 아래에서 보실 수 있습니다. 파이썬 Pandas로 머신러닝 기초 배
ruins880.tistory.com
'Biological Science > Bioinformatics' 카테고리의 다른 글
| 파이썬 Pandas로 머신러닝 기초 배워보기 (4/5) (0) | 2022.05.13 |
|---|---|
| 파이썬 Pandas로 머신러닝 기초 배워보기 (3/5) (0) | 2022.05.12 |
| 파이썬 Pandas로 머신러닝 기초 배워보기 (1/5) (0) | 2022.05.10 |
| 내 노트북에서 무작정 따라해보는 RNA-Seq 분석 - Part 2 (1) | 2022.05.09 |
| 내 노트북에서 무작정 따라해보는 RNA-Seq 분석 - Part 1 (0) | 2022.05.09 |
