
이 글은 Kaggle의 머신러닝 입문 (Intro to Machine Learning) 강의를 번역/정리한 글입니다. 원문은 여기서 찾아보실 수 있습니다.
이전 글은 아래에서 보실 수 있습니다.
파이썬 Pandas로 머신러닝 기초 배워보기 (2/5): https://ruins880.tistory.com/79
파이썬 Pandas로 머신러닝 기초 배워보기 (2/5)
이 글은 Kaggle의 머신러닝 입문 (Intro to Machine Learning) 강의를 번역/정리한 글입니다. 원문은 여기서 찾아보실 수 있습니다. 이전 글은 아래에서 보실 수 있습니다. 파이썬 Pandas로 머신러닝 기초
ruins880.tistory.com
이전 과제에서는 모델을 직접 만들어 보았습니다. 하지만, 우리가 만든 모델은 얼마나 정확할까요? 이번 시간에는 모델의 적합성 및 정확도를 측정하고 그것을 높이는 방법을 알아보겠습니다.
What is Model Validation (모델 확인이 뭐죠)
우리가 만드는 모델은 전부 평가가 필요합니다. 대부분의 경우에 이 평가의 척도는 모델이 예측하는 결과의 정확성에 달려있죠. 하지만 많은 사람들이 모델의 예측 정확도를 측정할 때에 모델을 만들 때 썼던 기존의 데이터를 이용하버리는 실수를 저지릅니다.
일단, 모델의 품질을 우리가 알아볼 수 있도록 정리해보겠습니다. 우리가 1만개의 집의 실제 가격과 예측된 가격을 비교하게 된다면, 정확한 예측가격과 그렇지 않은 것들이 섞여있을 것입니다. 1만개의 가격을 일일이 확인하는 것은 의미가 없을 것이므로, 우리는 이것을 하나의 수치로 종합할 방법이 필요합니다. 여기에는 여러가지 방법이 있지만, 지금은 절대오차평균(Mean Absolute Error; MAE)이라는 값을 이용하겠습니다. 이는 말 그대로, 각 오차의 절대치의 평균을 구한 값입니다. 각 모델의 오차는 error = actual - predicted 로 구할 수 있습니다. 그 오차들을 모두 양수로 전환해 평균을 낸 값입니다. 일단, MAE를 구하려면 모델이 있어야하니 모델부터 만들어 보겠습니다.
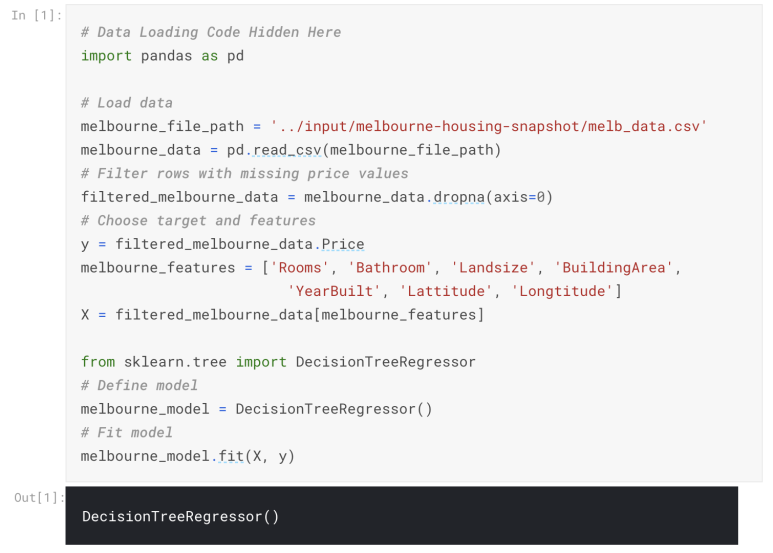
위의 코드로 모델을 만든 후, 절대오차평균은 다음과 같이 구합니다.

The Problem with "In-Sample" Scores ("샘플 내" 값을 사용하는 경우)
우리가 방금 계산한 값은 "샘플 내" 수치라고 부를 수 있습니다. 우리는 하나의 "샘플"을 모델을 만드는 데와 그것을 평가하는 데 둘 다 사용했죠. 하지만 이것은 좋지 않은 습관입니다.
예를 들어, 실제 부동산 시장에서는 현관문의 색깔이 집값에 영향을 미치지 않습니다. 하지만 모델을 만드는 샘플 데이터에서 초록색 문을 가진 집들이 전부 비싸다면, 그 결과 모델은 초록색 문이 있는 집의 가격을 항상 비싸게 예측할 것입니다. 이러한 패턴이 샘플 데이터에서 나왔기 때문에, 샘플 데이터로 모델의 정확도를 측정하면, 그 모델은 정확하게 보일 수 밖에 없습니다. 하지만, 샘플 데이터가 아닌 새로운 데이터를 모델에 대입했을 때에, 실제로 그 모델은 정확하지 않겠죠.
그러무로 우리는 모델의 정확도를 측정할 때에, 샘플 데이터가 아닌 새로운 데이터를 사용해야만 합니다. 이렇게 하기 위한 가장 쉬운 방법은 모델을 만들 때에 몇몇의 데이터를 제외하고, 그 제외된 데이터를 나중에 모델의 정확도를 테스트할 때에 쓰는 것입니다. 이렇게 제외된 데이터를 확인 데이터 (validation data)라고 부릅니다.
Coding It (코딩해보자)
scikit-learn 라이브러리에는 train_test_split 펑션이 있어서 데이터를 두 그룹으로 나눌 수 있습니다. 이 펑션을 이용하여 한 그룹은 모델을 만드는 데에 쓰고, 다른 그룹은 MAE를 계산하는 데 써보겠습니다.

위에서 샘플 내 값을 이용한 오차평균이 $434.72 였다면, 아래에 계산한 오차평균은 $261,425이 나왔습니다. 실제로 모델의 오차 평균이 $250,000 이상이라면 한참 문제가 있는 거겠죠. 참고로 데이터 내의 집값 평균은 $1,100,000이었으니, 오차가 집값의 거의 1/4 수준이 되는 것입니다.
다음은 직접 코딩 예제를 실행해 보겠습니다.
Kaggle은 따로 컴퓨터에 설치할 필요없이 웹상에서 파이썬 코드를 작성하고 실행시킬 수 있는 "notebook" 환경을 이용합니다. notebook 환경이 처음이신 분은 다음의 짧은 동영상을 보시면 됩니다: https://www.youtube.com/watch?v=4C2qMnaIKL4
지난 예제에서는 모델을 직접 만들어 보았죠. 거기에 이어서 하기 위해, 아래의 예제를 실행시켜 주세요.

Exercises
이번 예제에서는 지난 번에 직접 만든 모델의 정확도를 테스트해 보겠습니다. 예제는 아래의 링크에서 직접해보실 수 있습니다. Kaggle 계정을 생성하시면 더 도움이 될 수 있습니다. https://www.kaggle.com/kernels/fork/1259097
Kaggle Code
www.kaggle.com
Step 1: Split Your Data (데이터 반으로 나누기)
train_test_split 펑션을 사용해서 데이터를 나누세요.

Step 2: Specify and Fit the Model (모델을 지정하고 피팅하기)
DecisionTreeRegressor 모델을 만들고 알맞은 데이터를 피팅하세요. random_state는 1로 지정해주세요.

Step 3: Make Predictions with Validation Data (확인 데이터로 예측하기)

이제 실제 값과 예측 값을 살펴보겠습니다.
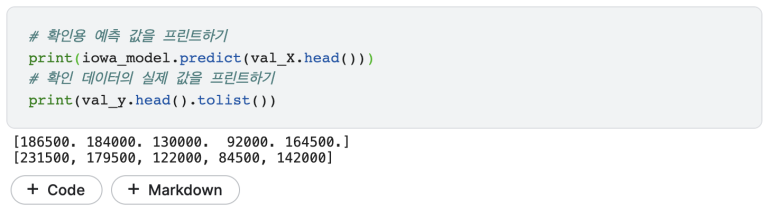
출력값의 첫줄은 모델이 예측한 값이며, 둘째 줄은 실제 집값입니다. 저 위에서 샘플 내 값으로 예측할 때랑 결과가 많이 달라졌나요? 이것은 아주 중요한 개념입니다.
Step 4: Calculate the Mean Absolute Error in Validation Data (절대오차평균 계산하기)
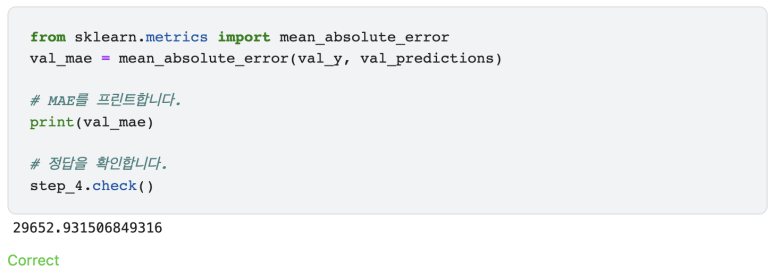
계산한 값이 괜찮은가요? 절대적으로 어떤 수치가 좋은 수치라는 것은 정해진 것이 아닙니다. 하지만 다음 단계를 계속해 나가면서 우리는 저 값을 줄일 것입니다.
이어지는 글: 파이썬 Pandas로 머신러닝 기초 배워보기 (4/5): https://ruins880.tistory.com/81
파이썬 Pandas로 머신러닝 기초 배워보기 (4/5)
이 글은 Kaggle의 머신러닝 입문 (Intro to Machine Learning) 강의를 번역/정리한 글입니다. 원문은 여기서 찾아보실 수 있습니다. 이전 글은 아래에서 보실 수 있습니다. 파이썬 Pandas로 머신러닝 기
ruins880.tistory.com
'Biological Science > Bioinformatics' 카테고리의 다른 글
| 파이썬 Pandas로 머신러닝 기초 배워보기 (5/5) (0) | 2022.05.17 |
|---|---|
| 파이썬 Pandas로 머신러닝 기초 배워보기 (4/5) (0) | 2022.05.13 |
| 파이썬 Pandas로 머신러닝 기초 배워보기 (2/5) (0) | 2022.05.11 |
| 파이썬 Pandas로 머신러닝 기초 배워보기 (1/5) (0) | 2022.05.10 |
| 내 노트북에서 무작정 따라해보는 RNA-Seq 분석 - Part 2 (1) | 2022.05.09 |
