
이 글은 Kaggle의 머신러닝 입문 (Intro to Machine Learning) 강의를 번역/정리한 글입니다. 원문은 여기서 찾아보실 수 있습니다.
Introduction
먼저, 머신러닝에서 모델이 어떻게 사용되는지 부터 시작하겠습니다. 만약 당신이 통계 모델링이나 머신러닝을 공부한 적이 있다면, 처음에는 너무 쉬울 수도 있습니다.
이 강의에서는 다음과 같은 상황에서 모델링을 어떻게 하는지를 배워볼 것 입니다.:
당신의 사촌형은 부동산에 투자해서 많은 돈을 벌었습니다. 그는 당신이 데이터사이언스를 공부하는 것을 알고 사업제안을 하나 했습니다. 사업에 필요한 자본은 사촌형이 제공하고, 당신은 각각의 집이 얼마나 가치가 있는지 결정하는 모델을 만들어야 합니다. 당신은 사촌형에게 그동안은 어떻게 집의 가치를 정했냐고 물어봤지만, 사촌형은 그냥 감으로 결정했다고 합니다. 하지만 사촌형에게 더 자세히 물어보니, 사촌형은 과거에 자신이 본 집값들에 어떠한 패턴이 있고, 그 패턴을 이용해 새로운 주택의 가격을 결정하고 있었습니다.
머신러닝도 똑같은 방법으로 작동합니다. 먼저 Decision Tree라는 모델링 기법을 사용해 보겠습니다. 더 정확한 결과를 보여주는 복잡한 모델들이 있긴하지만, Decision tree는 이해하기 쉽고, 몇몇 다른 좋은 모델의 기반이 되기도 합니다.
가장 간단한 Decision tree를 한번 보겠습니다.

위 모델은 집들을 침실이 두개 이상인지 아닌지의 두가지만으로 분류합니다. 여기서 결정된 가격 ($178000, $188000)은 그 분류항목에 속했던 모든 집들의 평균 가격으로 결정했습니다. 데이터를 이용해 집들을 두가지의 그룹으로 나누고, 그 다음 각각의 그룹에서 예상 가격을 결정합니다. 이렇게 데이터로부터 패턴을 잡아내는 것을 fitting 혹은 training이라고 합니다. 그리고 모델을 결정하기 위해 사용한 데이터는 training data라고 부릅니다. 모델이 어떻게 결정되는 지에 관한 자세한 사항들은 추후에 더 알아보기로 하고, 이제 우리는 새로운 데이터들을 이용해 다른 집들의 가격을 예측할 수 있습니다.
Improving the decision tree
다음 중 어느 Decision tree가 더 좋은 결과를 예측할 수 있을까요?

왼쪽의 Decision tree가 아마 더 말이 될 것입니다. 침실이 더 많은 집이 대체로 가격이 더 높기 때문이죠. 하지만 이 모델은 치명적인 단점이 있습니다. 그것은 침실 갯수 이외에 집값에 영향을 미치는 요인, 즉 화장실 갯수, 집 평수, 위치 등을 전혀 고려하지 않았기 때문입니다.

각 주택의 특징을 파악하여 Decision tree의 길을 따라가다보면 집값을 예측할 수 있습니다. 예측한 집의 가격은 트리의 가장 바닥에 있고, 예측을 가능하게 해주는 그 부분을 leaf라고 부릅니다.
다음은 실제 데이터를 관찰해 보겠습니다.
Using Pandas to Get Familiar With Your Data
(판다스를 이용하여 데이터에 익숙해지기)
모든 머신러닝 프로젝트의 첫 단계는 데이터에 익숙해지는 거십니다. 우리는 Pandas 라이브러리를 이용해보겠습니다. Pandas는 데이터 과학자들이 데이터를 조사하고 처리하는 데에 쓰는 도구입니다. 이 라이브러리를 다음과 같이 불러올 수 있습니다.
|
import pandas as pd
|
Pandas 라이브러리에서 가장 중요한 부분은 DataFrame입니다. 이 DataFrame에는 우리가 표로 알고있는 데이터를 저장할 수 있습니다. 엑셀의 시트나 SQL의 테이블과 비슷합니다. Pandas는 이러한 유형의 데이터로 우리가 원하는 대부분의 작업을 가능하게 만들어 줍니다. 예를 들어서 호주 멜버른의 주택 가격에 관한 데이터를 보겠습니다.
데이터를 읽어들여서 그 내용을 출력하는 명령어는 다음과 같습니다.
|
# 사용의 편의를 위해, 읽어들일 파일의 경로를 변수에 저장합니다.
melbourne_file_path = '../input/melbourne-housing-snapshot/melb_data.csv'
# 데이터를 읽어들여 melbourne_data 라는 변수에 DataFrame 형식으로 저장합니다.
melbourne_data = pd.read_csv(melbourne_file_path)
# 데이터의 개요를 출력합니다.
melbourne_data.describe()
|
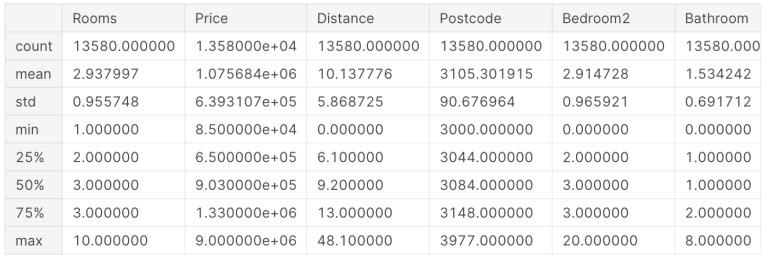
다음은 직접 예제를 실행해 보겠습니다.
Kaggle은 따로 컴퓨터에 설치할 필요없이 웹상에서 파이썬 코드를 작성하고 실행시킬 수 있는 "notebook" 환경을 이용합니다. notebook 환경이 처음이신 분은 다음의 짧은 동영상을 보시면 됩니다:
https://www.youtube.com/watch?v=4C2qMnaIKL4

Exercise: Explore Your Data
이번 예제는 데이터를 DataFrame 형식으로 불러들여, 우리가 어떤한 데이터를 가지고 있는지 살펴보는 것입니다. 예제는 아래의 링크에서 직접해보실 수 있습니다. Kaggle 계정을 생성하시면 더 도움이 될 수 있습니다.
https://www.kaggle.com/kernels/fork/1258954
Kaggle Code
www.kaggle.com
STEP 1: 데이터 불러오기

STEP 2: 데이터 살펴보기

생각해 볼 점
예제에서 살펴봤듯이, 우리 데이터에서 가장 최근에 지은 집은 2010년에 지어졌습니다. 여기에는 두가지 가능성이 있습니다.
1. 2010년 이후로 새 집을 전혀 짓지 않았다.
2. 데이터가 작성된 일시가 아주 예전이라, 최근의 데이터는 반영이 되어있지 않다.
만약 그 이유가 1번이라면, 우리는 이 데이터를 신뢰할 수 있을까요? 만약 이유가 2번이라면 어떨까요? 데이터를 좀더 자세히 들여다보면 이유가 1번인지 2번인지 알 수 있을까요?
다음은 머신러닝 모델을 직접 만들어보겠습니다.
파이썬 Pandas로 머신러닝 기초 배워보기 (2/5): https://ruins880.tistory.com/79
파이썬 Pandas로 머신러닝 기초 배워보기 (2/5)
이 글은 Kaggle의 머신러닝 입문 (Intro to Machine Learning) 강의를 번역/정리한 글입니다. 원문은 여기서 찾아보실 수 있습니다. 이전 글은 아래에서 보실 수 있습니다. 파이썬 Pandas로 머신러닝 기초
ruins880.tistory.com
'Biological Science > Bioinformatics' 카테고리의 다른 글
| 파이썬 Pandas로 머신러닝 기초 배워보기 (3/5) (0) | 2022.05.12 |
|---|---|
| 파이썬 Pandas로 머신러닝 기초 배워보기 (2/5) (0) | 2022.05.11 |
| 내 노트북에서 무작정 따라해보는 RNA-Seq 분석 - Part 2 (1) | 2022.05.09 |
| 내 노트북에서 무작정 따라해보는 RNA-Seq 분석 - Part 1 (0) | 2022.05.09 |
| [펌]박사 학위 또는 포닥을 Bioinformatics/Computational Biology로 해야하는 탑 N 가지 이유 (0) | 2017.06.15 |
