이 글은 Kaggle의 머신러닝 입문 (Intro to Machine Learning) 강의를 번역/정리한 글입니다. 원문은 여기서 찾아보실 수 있습니다.
이전 글은 아래에서 보실 수 있습니다.
파이썬 Pandas로 머신러닝 기초 배워보기 (3/5) https://ruins880.tistory.com/80
파이썬 Pandas로 머신러닝 기초 배워보기 (3/5)
이 글은 Kaggle의 머신러닝 입문 (Intro to Machine Learning) 강의를 번역/정리한 글입니다. 원문은 여기서 찾아보실 수 있습니다. 이전 글은 아래에서 보실 수 있습니다. 파이썬 Pandas로 머신러닝 기초 배
ruins880.tistory.com
이전 강의에서는 모델을 만들고 그 품질을 평가해보았습니다. 이번에는 과적합(overfitting)과 저적합(underfitting)의 개념에 대해 배워보겠습니다.
Experimenting with Different Models (여러 모델로 실험해보기)
scitkit-learn 문서를 보면 알 수 있듯이 decision tree 모델에도 엄청나게 많은 옵션이 있습니다. 가장 중요한 옵션은 tree의 깊이를 결정하는 것입니다. 강의 시리즈의 맨 처음에서 기억하실 지 모르겠지만, tree의 깊이란 모델에서 예측을 하기 전에 나뭇가지가 몇 번이나 나눠지는 지입니다. 아래는 비교적 '얕은' tree입니다.
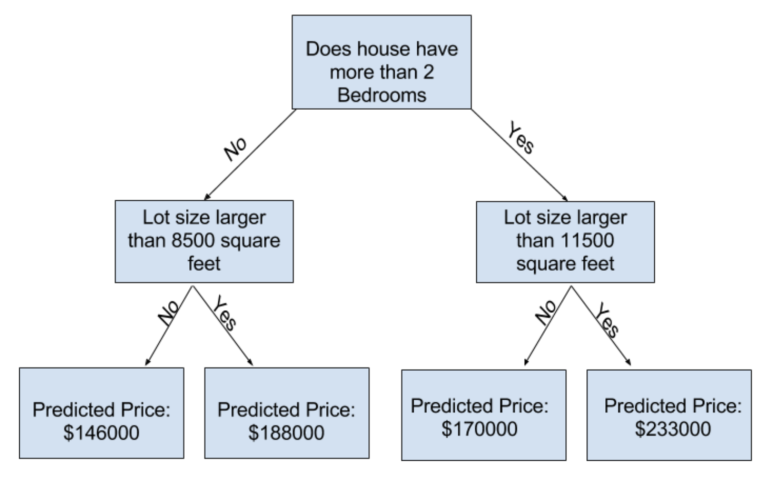
실제로는, 가지가 맨 위부터 맨 아래까지 10번 나눠져 있는 tree도 흔합니다. tree가 더 깊어질 수록, 제일 끝에 있는 잎에는 적은 수의 집들이 들어가죠. 만약 tree가 한번만 나눠진다면, 우리의 데이터는 절반으로 나눠져 두개의 그룹이 됩니다. 한번 더 나눠진다면, (위의 그림과 같이) 4개의 그룹이 되고요. 이런 식으로 계속 나눠간다면, 10번 나눠지고 나면 2^10 개의 그룹이 생길 것입니다. 이는 1024개의 잎을 의미합니다.
이렇게 여러 번 나누다 보면, 각 잎에는 아주 적은 수의 집들이 들어가게 될 것이고, 예측을 실제와 같이 정확하게 할 수 있을 것입니다. 하지만, 새로운 데이터가 주어졌을 때에는 예측이 아주 부정확해질 수도 있습니다 (각 그룹(잎)의 예측값은 아주 적은 수의 집값에만 기반하기 때문이죠).
이러한 현상을 과적합(overfitting)이라고 부릅니다. 훈련 데이터(training data)에는 모델이 거의 완벽하게 맞지만, 새로운 데이터에는 예측이 아주 부정확하죠.
반면에, 만약 tree를 아주 얕게 만든다면 그룹의 수가 적어서 각가의 집값의 특징이 잘 나타나지 않게 됩니다. 극단적인 예를 들어보면, 만약 tree가 모든 집들을 두 개 혹은 네 개의 그룹으로만 나눈다면, 그룹 안에서는 여전히 다양한 범위의 집값이 존재할 것입니다. 예측치는 실제 집값과는 거리가 멀 것이며, 이것은 훈련 데이터를 사용한 예측에도 동일합니다. 모델이 중요한 특징이나 패턴을 잡아내지 못하고 훈련 데이터에서조차 예측 정확도가 아주 낮다면 이것을 저적합(underfitting)이라고 부릅니다.
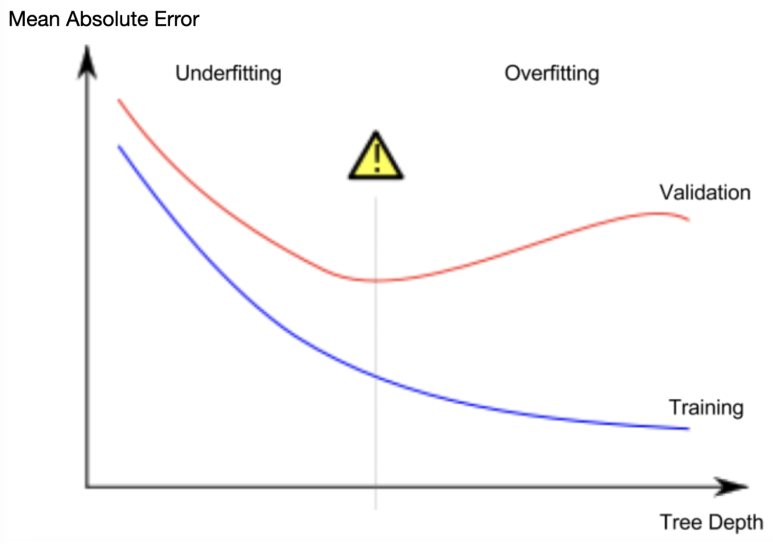
우리는 훈련 데이터로부터 생성해 낸 모델로 새로운 데이터 예측의 정확도를 높이고 싶으므로, 이 과적합과 저적합 사이의 알맞은 위치를 찾아내어야 합니다. 아래의 그래프에서, 빨간 선의 가장 낮은 부분을 의미하죠.
Example (예제)
Tree의 깊이를 조절하는 데에는 몇가지 방법이 있습니다. 그중에서 max_leaf_nodes 옵션이 과적합과 저적합을 조절하는 데에 아주 적절한 방법입니다. 더 많은 leaf node를 허락할 수록, 모델은 위의 그래프의 Overfitting 위치에서 Underfitting 쪽으로 이동합니다. 아래의 코드를 이용해서 MAE 점수를 내고 서로 다른 값을 max_leaf_nodes 에 넣어서 비교를 해볼 수 있습니다.
|
from sklearn.metrics import mean_absolute_error
from sklearn.tree import DecisionTreeRegressor
def get_mae(max_leaf_nodes, train_X, val_X, train_y, val_y):
model = DecisionTreeRegressor(max_leaf_nodes=max_leaf_nodes, random_state=0)
model.fit(train_X, train_y)
preds_val = model.predict(val_X)
mae = mean_absolute_error(val_y, preds_val)
return(mae)
|
데이터는 우리가 아까 쓴 코드를 이용해서 train_X, val_X, train_y, val_y 변수에 저장됩니다.
|
# Data Loading Code Runs At This Point
import pandas as pd
# 데이터를 불러옵니다
melbourne_file_path = '../input/melbourne-housing-snapshot/melb_data.csv'
melbourne_data = pd.read_csv(melbourne_file_path)
# 값이 없는 행을 걸러냅니다
filtered_melbourne_data = melbourne_data.dropna(axis=0)
# 타겟과 feature를 선택합니다
y = filtered_melbourne_data.Price
melbourne_features = ['Rooms', 'Bathroom', 'Landsize', 'BuildingArea', 'YearBuilt', 'Lattitude',
'Longtitude']
X = filtered_melbourne_data[melbourne_features]
from sklearn.model_selection import train_test_split
# 데이터를 training data와 validation data로 나눕니다.
train_X, val_X, train_y, val_y = train_test_split(X, y,random_state = 0)
|
for 반복문을 이용하여, max_leaf_nodes 값의 변화에 따라 모델의 정확도를 비교해볼 수 있습니다.
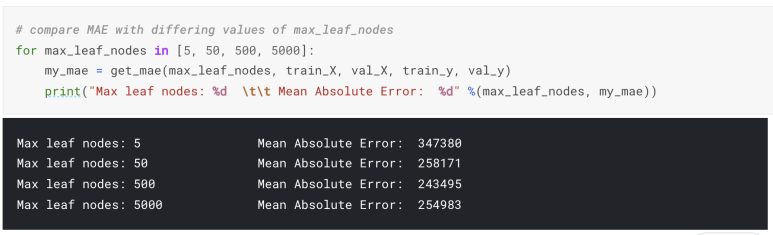
위의 결과에서는 500개가 가장 최적의 값입니다.
Conclusion (결론)
모델은 두가지 문제점이 있을 수 있습니다
과적합(Overfitting): 앞으로는 절대 일어나지 않을 잘못된 패턴을 잡아내어서 예측을 부정확하게 만듭니다.
저적합(Underfitting): 관련이 있는 패턴을 잡아내지 못해 전반적인 정확도가 떨어집니다.
이제 직접 코드를 짜보겠습니다.
코드 예제 연습은 notebook 환경을 제공하는 Kaggle에서 직접해보시는 것을 추천합니다. 다음의 링크에서 찾으실 수 있습니다: https://www.kaggle.com/kernels/fork/1259126
Kaggle Code
www.kaggle.com
이번 예제에서는 더나은 예측을 위해 tree의 크기를 조절해볼텐데, 다음의 코드는 이전에 우리가 직접 만든 모델을 다시 만들어줍니다.

Exercises (예제)
MAE를 계산해주는 get_mae 펑션을 직접짤 수도 있지만, 일단 여기서는 미리 제공하겠습니다.

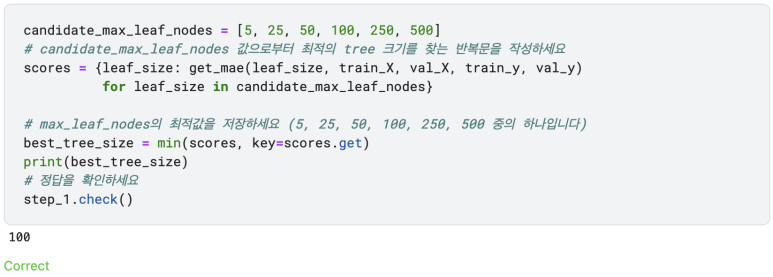
Step 1: Compare Different Tree Sizes
아래의 값들을 max_leaf_nodes로 실행하는 반복문을 만드세요. 각각의 max_leaf_nodes 값에 대응하는 get_mae 펑션을 호출하세요. 가장 정확한 예측을 하는 모델을 선택하기 위해 max_leaf_nodes 값을 저장하세요.
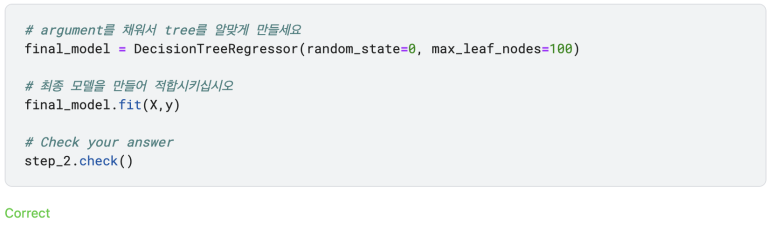
Step 2: Fit Model Using All Data (모든 데이터를 이용하여 모델을 적합시키기)
이제 가장 알맞은 tree의 크기를 알았으니, 모델을 더욱 정확하게 하기 위해 알아낸 크기와 우리가 가진 모든 데이터를 이용하여 모델의 정확도를 높여봅시다. 즉, validation data를 따로 떼어놓지 않아도 됩니다.
지금까지 모델을 만들어서 그 예측도를 향상시키는 방법을 배워보았습니다. 하지만 우리가 사용한 모델은 현대 머신러닝 기준으로 딱히 정확하지 않은 Decision Tree model 입니다. 다음 단계에서는 우리의 모델을 더욱더 향상시키기 위해 Random Forests 라는 기법을 써보도록 하겠습니다.
다음 글: 파이썬 Pandas로 머신러닝 기초 배워보기 (5/5): https://ruins880.tistory.com/82
파이썬 Pandas로 머신러닝 기초 배워보기 (5/5)
이 글은 Kaggle의 머신러닝 입문 (Intro to Machine Learning) 강의를 번역/정리한 글입니다. 원문은 여기서 찾아보실 수 있습니다. 이전 글은 아래에서 보실 수 있습니다. 파이썬 Pandas로 머신러닝 기초 배
ruins880.tistory.com
'Biological Science > Bioinformatics' 카테고리의 다른 글
| 싱글셀 RNA-Seq에서의 Batch Effect (0) | 2022.06.18 |
|---|---|
| 파이썬 Pandas로 머신러닝 기초 배워보기 (5/5) (0) | 2022.05.17 |
| 파이썬 Pandas로 머신러닝 기초 배워보기 (3/5) (0) | 2022.05.12 |
| 파이썬 Pandas로 머신러닝 기초 배워보기 (2/5) (0) | 2022.05.11 |
| 파이썬 Pandas로 머신러닝 기초 배워보기 (1/5) (0) | 2022.05.10 |
