이 글은 Kaggle의 머신러닝 입문 (Intro to Machine Learning) 강의를 번역/정리한 글입니다. 원문은 여기서 찾아보실 수 있습니다.
이전 글은 아래에서 보실 수 있습니다.
파이썬 Pandas로 머신러닝 기초 배워보기 (4/5): https://ruins880.tistory.com/81
파이썬 Pandas로 머신러닝 기초 배워보기 (4/5)
이 글은 Kaggle의 머신러닝 입문 (Intro to Machine Learning) 강의를 번역/정리한 글입니다. 원문은 여기서 찾아보실 수 있습니다. 이전 글은 아래에서 보실 수 있습니다. 파이썬 Pandas로 머신러닝 기
ruins880.tistory.com

Introduction
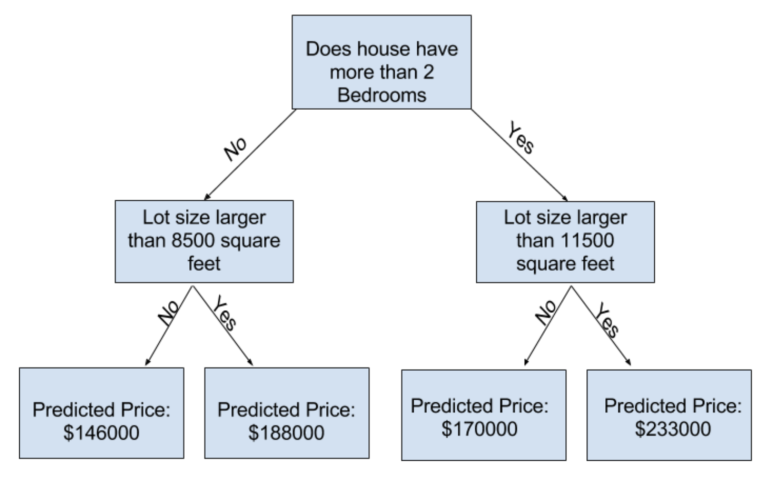
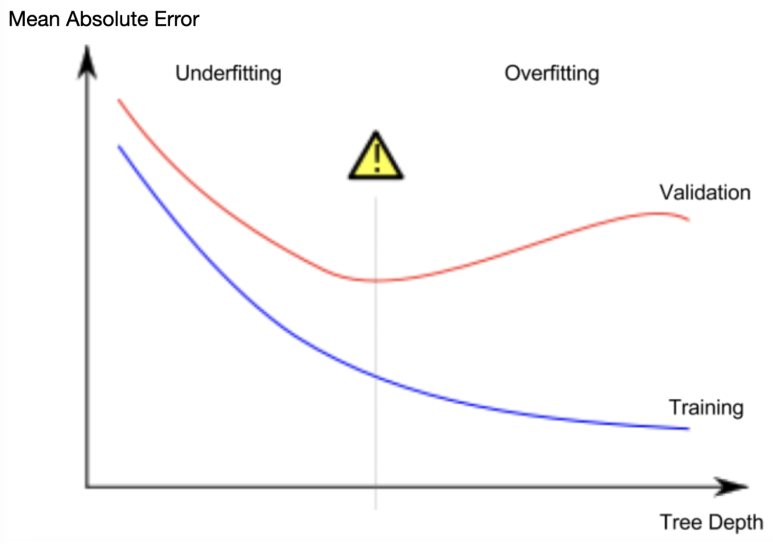
Decision tree는 사용하면 어려운 결정을 내려야할 때가 있습니다. 잎사귀가 많은 깊은 tree는 과적합의 문제가 있을 수 있고, 너무 얕은 tree는 예측의 정확도가 아주 떨어집니다. 현대의 가장 복잡한 모델링 기술로도 이러한 과적합(overfitting)과 저적합(underfitting)의 문제를 직면할 수 밖에 없습니다. 하지만 많은 모델링 방법들은 이러한 문제를 해결하기 위해 여러 방법을 사용합니다. 이번에는 Random Forest라는 모델링 기법으로 이것을 어떻게 해결하는지 살펴보겠습니다.
Random Forest는 많은 tree를 사용하여 그 tree들의 예측값의 평균을 구합니다. 그래서 단 하나의 tree를 사용할 때보다 대체로 더 나은 예측치를 보여주며, 기본 옵션으로도 훨씬 나은 성능을 보입니다. 앞으로 우리가 머신러닝과 모델링을 더 공부하면서, 여러 모델링 방법들을 배울텐데, 많은 경우에 적절한 옵션 및 매개변수를 사용하는 것이 필수입니다.
Example
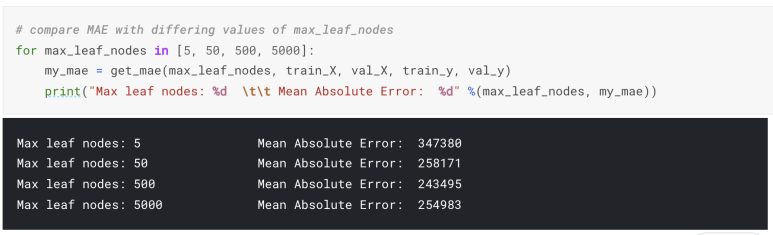
다음 코드는 이미 몇번 보셨지만, 다시 로딩해보겠습니다. 끝에는 다음 4개의 변수가 나옵니다:
train_X, val_X, train_y, val_y
|
import pandas as pd
# 데이터를 불러오기
melbourne_file_path = '../input/melbourne-housing-snapshot/melb_data.csv'
melbourne_data = pd.read_csv(melbourne_file_path)
# 값이 없는 열을 제거합니다
melbourne_data = melbourne_data.dropna(axis=0)
# 타겟과 피쳐를 선택합니다
y = melbourne_data.Price
melbourne_features = ['Rooms', 'Bathroom', 'Landsize', 'BuildingArea', 'YearBuilt', 'Lattitude', 'Longtitude']
X = melbourne_data[melbourne_features]
from sklearn.model_selection import train_test_split
# 예측 목표와 변수들을 훈련 데이터와 확인 데이터로 나눕니다
# 나누는 것은 랜덤 숫자 생성기에 기반합니다
# random_state 옵션에 숫자를 지정하면 매번 같은 결과가 나오도록 합니다
train_X, val_X, train_y, val_y = train_test_split(X, y,random_state = 0)
|
scikit-learn을 사용해서 decision tree를 만든 것처럼 random forest 모델을 만들 수 있습니다. DicisionTreeRegressor 대신에 RandomForestRegressor를 사용해서 말이죠.

Conclusion (결론)
모델을 더 향상시킬 여지는 있겠지만, decision tree에서 나온 에러값인 250,000에 비하면 많은 발전입니다. decision tree의 깊이를 조정하는 등의 옵션으로 모델의 성능을 조절할 수도 있습니다. 하지만 random forest의 가장 큰 장점은 이러한 미세한 조정과정이 없어도 대체로 좋은 성능을 보여준다는 거죠.
이제 직접 Random forest model을 만들어 볼 차례입니다.
Kaggle은 따로 컴퓨터에 설치할 필요없이 웹상에서 파이썬 코드를 작성하고 실행시킬 수 있는 "notebook" 환경을 이용합니다. 예제는 아래의 링크에서 직접해보실 수 있습니다. Kaggle 계정을 생성하시면 더 도움이 될 수 있습니다.
https://www.kaggle.com/code/fork/1259186
Kaggle Code
www.kaggle.com
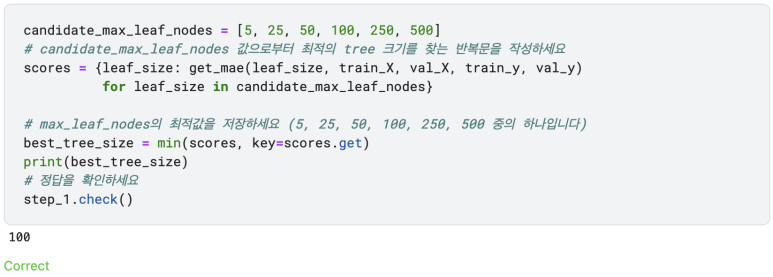
이전 예제에서 우리가 작성했던 코드입니다:

Exercieses
데이터사이언스는 항상 이렇게 쉽지많은 않습니다. 하지만 decision tree를 random forest로 바꾸는 건 아주 쉬운 방법이죠.
Step 1: Use a Random Forest

이제까지 모델링에 관해서 배워보았습니다. 정해진 예제와 절차에 따라 모델을 만들어 보았고, 우리는 처음 모델을 만드는 데 있어서 중요한 개념들을 배워보았습니다. 이제 스스로 만들어 볼 차례입니다. 머신러닝 대회는 자신의 아이디어를 시도해보고 스스로 머신러닝 프로젝트에 대해 탐구해 볼 좋은 기회입니다. 다음 링크에서 직접 머신러닝 아이디어를 테스트해보세요:
Housing Prices Competition for Kaggle Learn Users
www.kaggle.com
'Biological Science > Bioinformatics' 카테고리의 다른 글
| Single Cell RNA-Seq Analysis (4) | 2022.07.02 |
|---|---|
| 싱글셀 RNA-Seq에서의 Batch Effect (0) | 2022.06.18 |
| 파이썬 Pandas로 머신러닝 기초 배워보기 (4/5) (0) | 2022.05.13 |
| 파이썬 Pandas로 머신러닝 기초 배워보기 (3/5) (0) | 2022.05.12 |
| 파이썬 Pandas로 머신러닝 기초 배워보기 (2/5) (0) | 2022.05.11 |